| T O P I C R E V I E W |
| aleatprog |
Posted - Nov 18 2022 : 07:43:31
Hi,
I need to automatically preprocess color scans in order to get the cleanest text for extraction.

Text recognition fails because the red line is too close to the text. Therefore, I tried to remove all red pixels using Proc.CastColorRange, but its tolerance starts to remove grey text pixels before all red pixels are removed. I tried also to clean up and increase image quality by implementing other preprocessing stages using AdjustBrightnessContrastSaturation, ConvertToGray & BN, WhiteBalance_AutoWhite, RemoveNoise, but all results got a poor or unstable recognition precision.
Has anybody an idea with which function the light red pixels can be removed by code without decreasing the text quality?
Al |
| 5 L A T E S T R E P L I E S (Newest First) |
| xequte |
Posted - Jan 09 2024 : 14:54:50
Also, I was able to successfully extract the text via OCR from all of these.
Nigel
Xequte Software
www.imageen.com
|
| srtt |
Posted - Jan 09 2024 : 07:31:30
thanks. |
| xequte |
Posted - Jan 08 2024 : 17:45:38
Hi
You can clean up the image a lot using...
Contrast3():
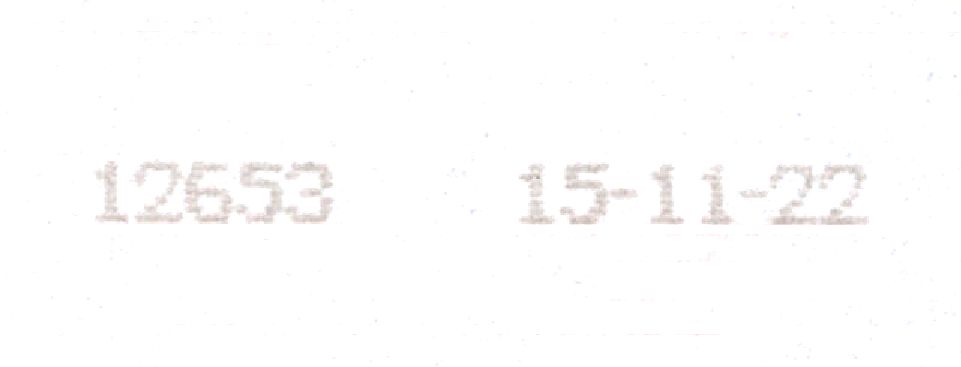
ConvertToBWThreshold():


StretchValues():

WhiteBalance_WhiteAt():
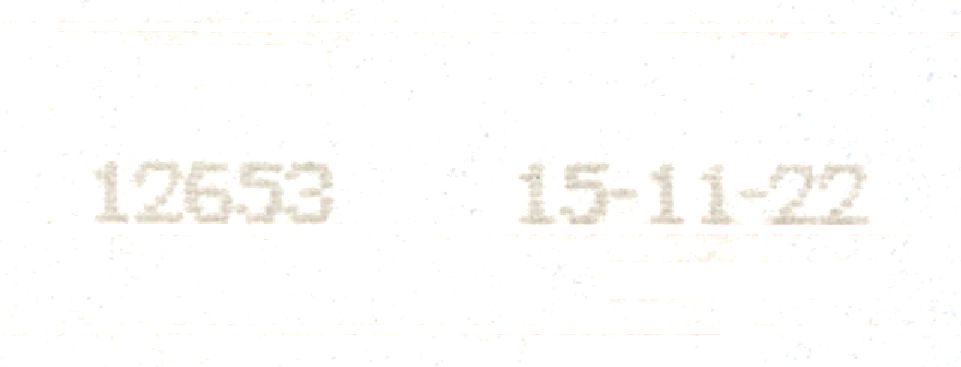
Nigel
Xequte Software
www.imageen.com
|
| srtt |
Posted - Jan 08 2024 : 05:57:56
Has anyone found a solution to this problem or has any other suggestions?
I have that same problem. |
| xequte |
Posted - Nov 18 2022 : 17:28:34
Hi Al
Yes, that is not an easy document to scan. I would try parsing the scanlines yourself to find "Reddish" pixels, e.g. where R > 200, G < 100, B < 100, and make them white.
See the example at:
http://www.imageen.com/help/TIEBitmap.Scanline.html
If that is successful in nullifying the red pixels, then you might also then need to do some thresholding to try to increase the contrast between the text and the background.
Nigel
Xequte Software
www.imageen.com
|